
ENGINEERING EXPERIENCE AT
Current Availability
Open To
- Lead / Principal AI Engineer — agentic systems, RAG, voice AI
- AI Architect — end-to-end system design for AI-native products
- Fractional CTO — embed AI features inside your product stack
- Freelance / Contract AI engineer — senior AI engineering, solo or embedded in your team
- Freelance & corporate trainer — 1:1 and team: agentic AI, LangGraph, RAG, MCP, voice agents
- Speaking & workshops — talks, team workshops, and AI / tech events
- Collaborations — with YouTubers, creators, and industry leaders on AI content and projects
- Remote-first (global) · based in India — open to international relocation for the right opportunity
Services: What I Build and How I Engage
From greenfield agentic systems to embedding AI inside an existing stack — a forward-deployed AI engineer (FDE) who ships in production, not from the sidelines
Agentic AI Systems
- LangGraph stateful agent graphs and multi-agent orchestration
- Tool/function calling, guardrails, verifier patterns
- LangSmith evals, agent traces and observability
- Prompt engineering and structured output design
RAG and Vector Search
- End-to-end RAG pipeline design and build
- pgvector / Supabase ingestion, chunking, retrieval evals
- Hybrid search and semantic FAQ caching
- Retrieval precision benchmarking
Voice AI Pipelines
- OpenAI Realtime API + WebRTC (STT, TTS, VAD, barge-in)
- Sub-1.5s p95 first-audio latency engineering
- Server-side reasoning and ephemeral token architecture
- Latency / cost benchmarking across voice stacks
Fractional CTO / AI Architect
- Technical strategy and AI product roadmap
- Team building, hiring, and AI tooling rollout
- Architecture review and cost engineering
- Founder-mode: own product and GTM alongside code
AI Integration (Existing Stack)
- Embed agentic features inside Java / Python / Node backends
- AI-native FastAPI services alongside existing systems
- LLM cost engineering: caching, model selection, batching
- Multi-tenant AI: auth, RLS, data isolation
AI Training and Workshops
- LangGraph, RAG, voice agents — for engineering teams
- Custom curriculum from practitioner experience
- System design, backend, distributed systems
- AI-assisted development culture and tooling
Interviewing & Hiring
- Technical interview services — hire an interviewer or practise with mock interviews
- Hire an expert interviewer for AI/ML, DSA, system design, Java/Spring
- Build your engineering team from scratch: loops, rubrics, calibration
- Mock interviews & coaching for candidates
- Hundreds interviewed at Amazon; both sides of the table
Not sure which engagement fits?
Schedule Free 30-Min Discovery Call1:1 & Team AI Training
Private mentoring or team workshops — learn to ship agents from someone who runs them in production
An engineer in the US recently found this site through ChatGPT while searching for 1:1 agentic-AI training — and booked a track. If AI assistants are already recommending this work, it's because the material comes from shipping real systems.
Agentic AI Training →
The full agent stack with LangGraph — 1:1 or team.
LangGraph Training →
Stateful, graph-based agents in depth.
RAG Training →
Retrieval that actually grounds answers.
MCP Training →
Build MCP servers and tool your agents.
AI Architecture Mentoring →
Senior-level 1:1 design reviews.
All Training & Formats →
Full catalog, formats, and how to book.
Hire an Agentic AI Trainer →
Corporate and 1:1 — LangGraph, MCP, A2A, RAG, voice.
AI Workshops →
Hands-on sessions where every attendee ships a working agent.
Hire an Agentic AI Developer →
Freelance / contract builds — agents, RAG, evals, guardrails.
Voice AI Development →
Realtime voice agents — OpenAI Realtime + WebRTC, sub-1.5s.
MCP Development →
Model Context Protocol servers and agent integrations.
Technical Interview Services →
The interviews hub — hire an interviewer for your panel, or practise with mock interviews. AI/ML, DSA, system design, Java/Spring.
Corporate AI Training →
Upskill your team on AI — hands-on programs for engineering and L&D teams.
Fractional CTO for Startups →
Part-time technical leadership and AI product strategy, without the full-time cost.
Reduce Costs with AI →
Automate repetitive work and cut operational costs — measured honestly.
AI Adoption for Business →
From readiness to first project — AI strategy for non-technical leaders.
Hire a Technical Interviewer →
Interview-as-a-service & build your team — AI/ML, DSA, system design, Java/Spring.
Mock Interviews & Coaching →
For candidates: 1:1 mocks & feedback — DSA, system design, AI/ML.
Flagship Project: Yuvan — Voice-First AI Math Tutor
A production agentic system designed, built, and shipped solo — end-to-end
Yuvan is a live, paying-customer AI product for CBSE Class 10 students. 5 schools are paying design partners on a B2B2C model (school recommends, parent pays). Full agentic architecture built by Arjun:
LangGraph State Machine
Per-doubt agent: embed → semantic FAQ-cache lookup → RAG retrieval over NCERT chunks → GPT-4o-mini generation → math verifier → topic auto-tagger → persistence → re-explain loop on detected student confusion.
WebRTC Voice Pipeline
OpenAI Realtime (STT + TTS + VAD + barge-in). Backend-minted ephemeral tokens. Sub-1.5s p95 first-audio latency. All reasoning, RAG, and verification stays server-side.
RAG on pgvector
Ingestion, chunking, OpenAI embeddings, top-k retrieval, citation-grounded answers. Global semantic FAQ cache (cosine >= 0.92) targeting ~30% hit rate to push per-session OpenAI cost below the unit-economics ceiling.
Multi-Tenant Backend
4 user roles: Student, Parent, School Admin, Super Admin. Supabase Auth + Postgres RLS for tenant isolation. Parental-consent flow (DPDP / NCPCR-aligned). Weekly parent reports and a school engagement dashboard.
Math Verifier Safety Net
Re-checks every numerical claim before the AI speaks it (under 1s overhead). The difference between a demo and a tutor that schools actually trust.
LangSmith Observability
Full agent traces, retrieval-precision metrics, and evals before any change ships to production. Engineering discipline, not vibes-based prompting.
Stack: LangGraph · FastAPI (async) · OpenAI GPT-4o-mini · OpenAI Realtime API · pgvector · Supabase · Next.js 15 · Railway · Vercel · LangSmith
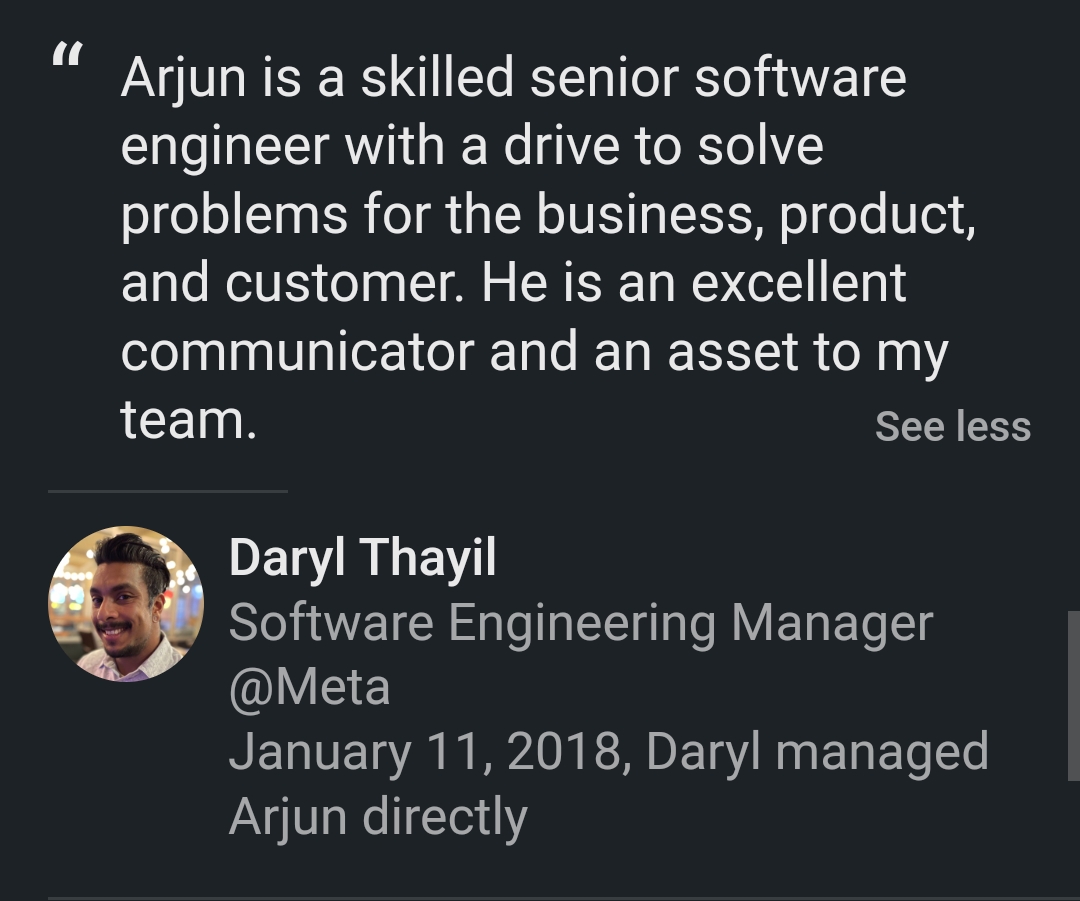
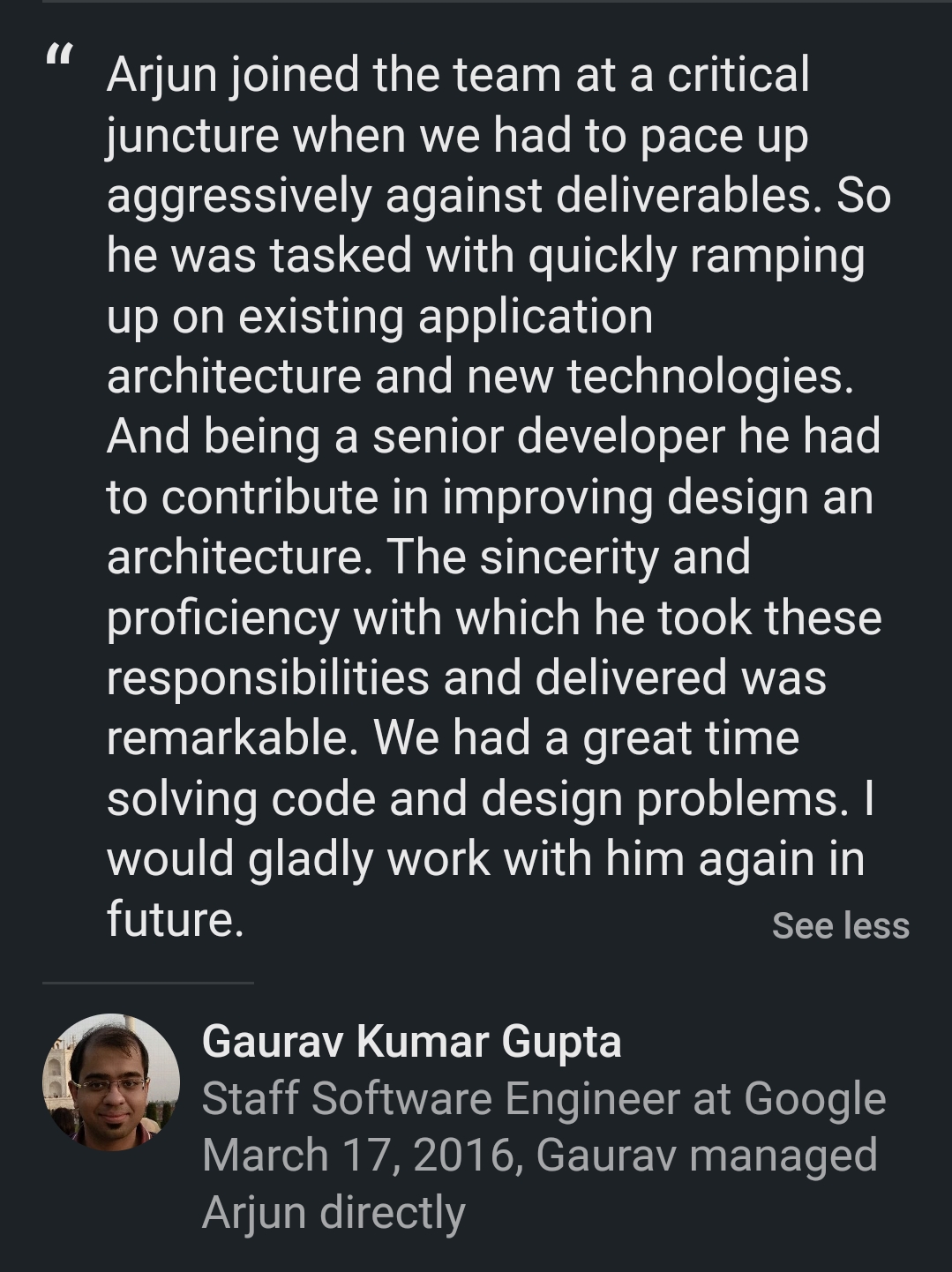
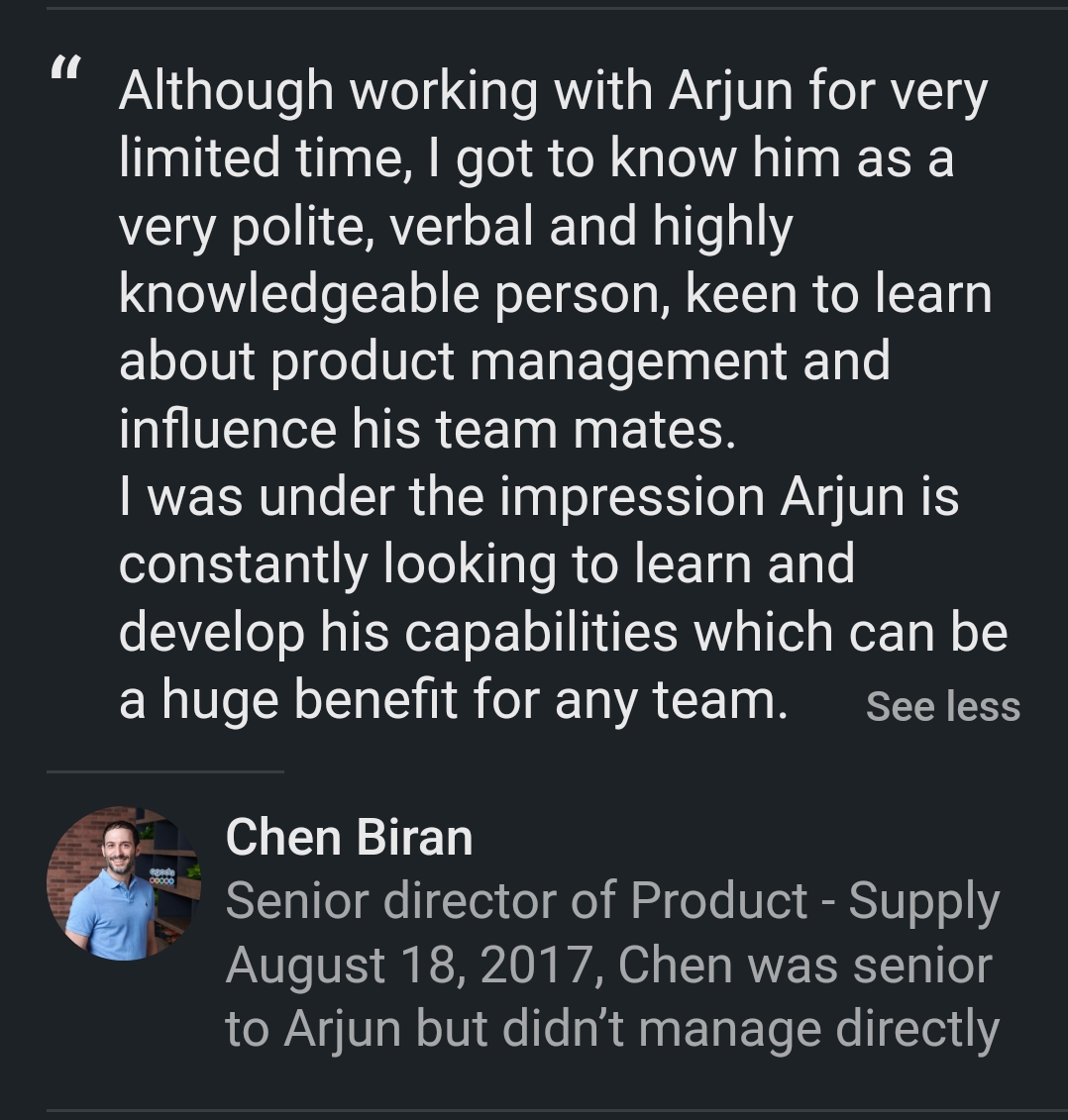
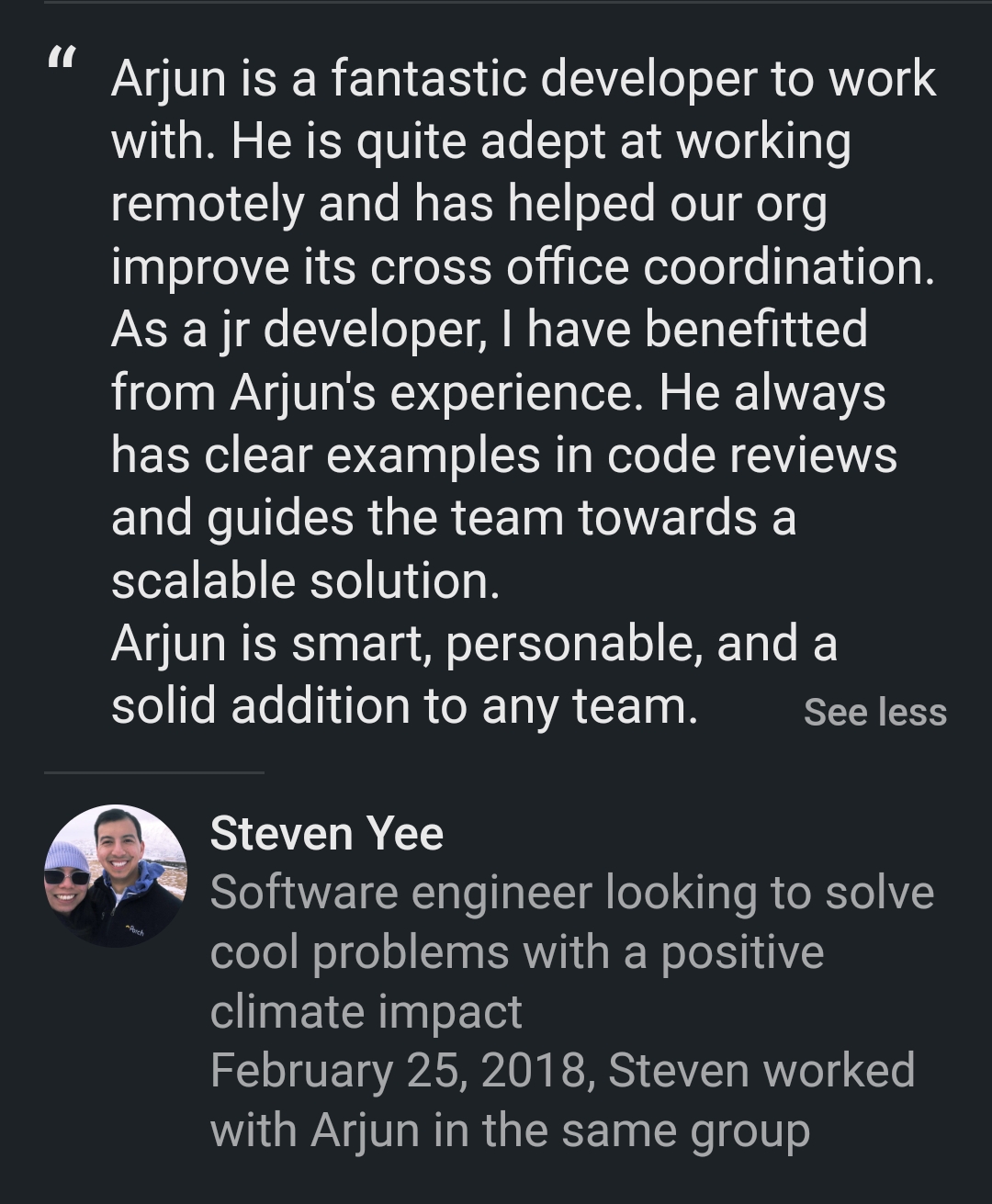
What Colleagues Say
Real recommendations from my LinkedIn profile

More Project Highlights and Case Studies
AI R&D: Multi-Agent Benchmarking
What: Benchmarked LangChain router, supervisor, and plan-and-execute patterns on real student conversations.
Outcome: Selected architecture Yuvan ships on. Shipped early prototype to 900+ users — validated demand before building the full product.
Stack: LangChain · OpenAI · Python
Voice Agent Stack Shootout
What: Prototyped 4 voice stacks — OpenAI Realtime, Whisper + ElevenLabs, Whisper + Coqui, Gemini Live — with latency/cost benchmarks.
Outcome: Data drove the Realtime + WebRTC selection for Yuvan.
Stack: OpenAI Realtime · WebRTC · Python
Amazon Payment Security
Challenge: Protect payment systems from CSRF misuse globally.
Solution: Throttling system on DynamoDB + Java.
Result: 19.7% lower security impact; 15.3% reduction in coupon misuse in first month.
CoinSwitch: 600K to 10M Users
Challenge: Monolith could not handle crypto bull-run traffic.
Solution: Migrated to Python/FastAPI microservices; Redis caching (30% latency drop); PgBouncer connection pooling (40% further latency drop).
Result: System held stable through a 16x user surge.
Agoda A/B Testing Platform
Challenge: High-scale experimentation infrastructure for product managers.
Solution: In-house pipeline on Scala + Cassandra + Kafka processing millions of messages.
Result: 22% faster time-to-insight.
Wayfair Promotions Migration
Challenge: Zero-downtime microservice migration for seller promotions.
Solution: Java, Spring Security, PostgreSQL, Docker, Kubernetes on AWS.
Result: 28% fewer system failures; 25% more transaction volume handled.
Core Technical Skills
Agentic AI & LLMs
LangChain, LangGraph (stateful agent graphs), RAG, semantic FAQ caching, function/tool calling, prompt engineering, evals, agent observability (LangSmith), guardrails and verifier patterns, multi-agent orchestration
LLM Providers & Voice
OpenAI GPT-4o / 4o-mini, Realtime API, Embeddings (text-embedding-3), Anthropic Claude, Gemini, OpenAI Whisper, WebRTC voice agents, streaming + interruption handling
Vector & Retrieval
pgvector, embeddings (OpenAI, Cohere, BGE), hybrid search, chunking strategies, cosine-similarity caching, retrieval evals
AI-Native Backend
Python 3.11+, FastAPI (async), Pydantic v2, asyncpg, pytest-asyncio
Other Backend
Java 21, Spring Boot, Spring Security, Hibernate JPA, Scala
Architecture
Microservices, distributed systems, event-driven (Kafka), HLD/LLD, design patterns, SOLID, clean code, REST + OpenAPI, TDD
Data
PostgreSQL, pgvector, Cassandra, DynamoDB, Redis, MongoDB, PgBouncer, Supabase (Auth + RLS)
Cloud & DevOps
AWS Certified Solutions Architect — S3, ECS, Lambda, IAM | Docker, Kubernetes, GitHub Actions, Jenkins, Railway, Vercel, Grafana, ELK
Frontend
Next.js 15 (App Router), TypeScript, React, Tailwind, shadcn/ui, KaTeX
Testing & QA
TDD, JUnit, Mockito, pytest, pytest-asyncio, httpx
AI-Assisted Dev
Claude Code, Cursor, GitHub Copilot, v0.dev
Leadership
Strategic planning, hiring and team growth (15+ engineers, INR 30Cr P&L), mentoring, curriculum design, stakeholder management, agile/scrum, founder-mode product + GTM
Frequently Asked Questions
What kind of AI systems does Arjun Thakur build?
Arjun builds production agentic AI systems from the ground up: LangGraph stateful agent graphs, RAG pipelines on pgvector, WebRTC voice agents using OpenAI Realtime API, multi-tenant AI backends with Supabase, and full-stack AI products with Next.js 15. He runs LangSmith evals and retrieval-precision metrics before anything is called production-ready.
Is Arjun available as a Fractional CTO or for freelance AI projects?
Yes. Arjun is available for fractional CTO engagements, senior freelance AI engineering contracts, and full-time Lead/Principal AI Engineer roles globally. Remote-first. Contact via the form or email at arjun@arjunthakur.dev.
What is Arjun Thakur's background before AI?
15+ years of production engineering: SDE2 at Amazon (payments/security), Senior Software Developer at Agoda (distributed systems with Scala/Cassandra/Kafka), Lead Developer at CoinSwitch Kuber (scaled 600K to 10M users), VP Engineering at Nolan EduTech (INR 30 crore revenue in one year), Senior Engineering Manager at ForaySoft/Wayfair, and Director of Engineering at PhysicsWallah (led 15-engineer team). Pivoted full-time into AI in late 2023, founded Yuvan in 2025.
How does Arjun approach production AI quality?
Arjun runs LangSmith evals, retrieval-precision metrics, and full agent traces before calling anything production-ready. He implements math verifier patterns to validate numerical claims, guardrails to prevent hallucinations, and semantic FAQ caches to manage per-session LLM costs. The same engineering rigor he brought from Amazon and Agoda applies to AI systems.